
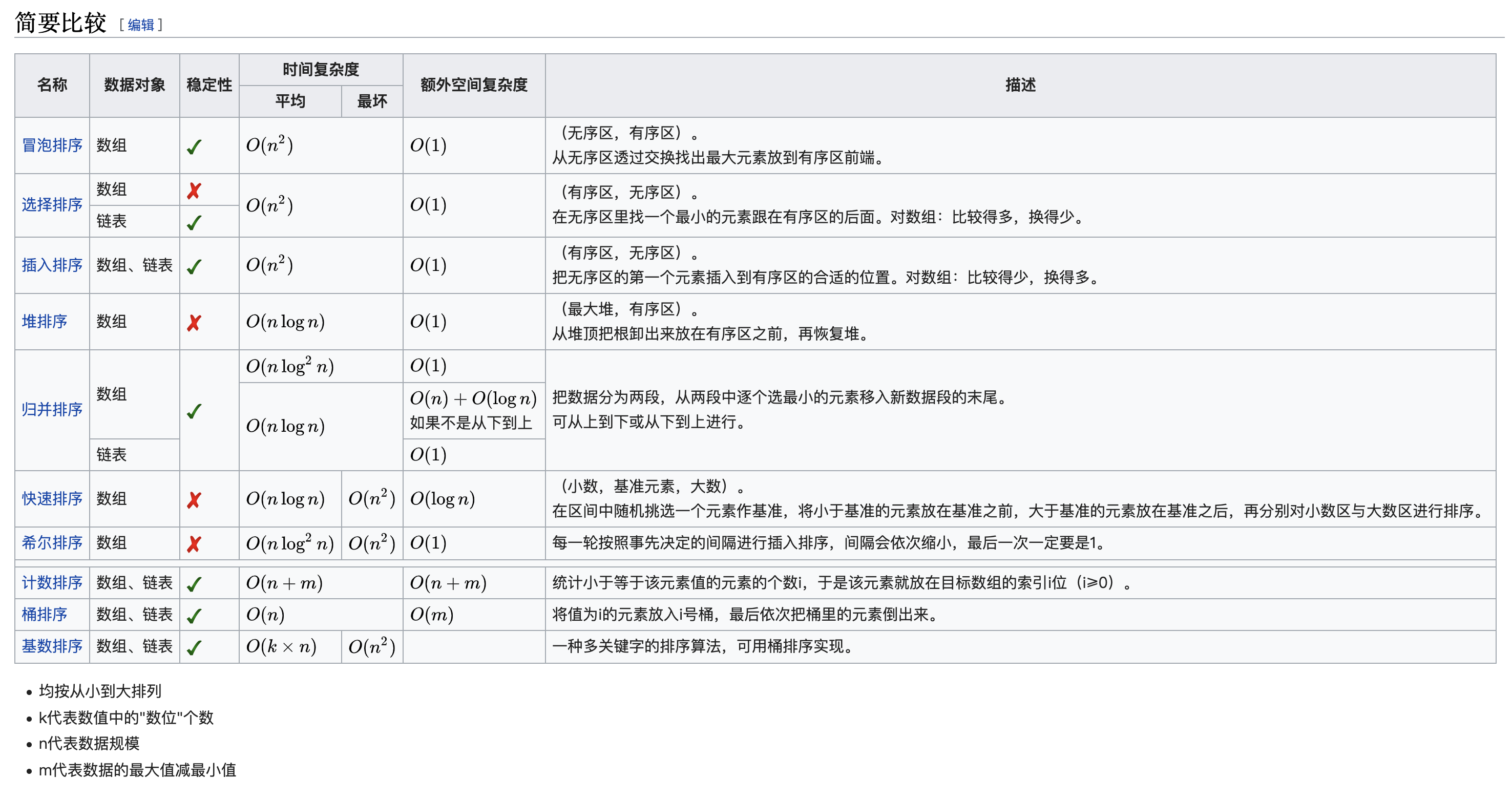
分析一个“排序算法”
执行效率
最好情况、最坏情况、平均情况时间复杂度:
在分析排序算法的时间复杂度时,要分别给出最好情况、最坏情况、平均情况下的时间复杂度,同时还要大概了解一下这些情况下的原始数据的组成。
- 对于要排序的数据,有的接近有序,有的完全无序。有序度不同的数据,对于排序的执行时间肯定是有影响的,我们要知道排序算法在不同数据下的性能表现。
时间复杂度的系数、常数 、低阶:
时间复杂度反映的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。
但是实际的软件开发中,排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,就要把系数、常数、低阶也考虑进来。
比较次数和交换(或移动)次数:
基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。所以,在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
排序算法的内存消耗
算法的内存消耗可以通过空间复杂度来衡量,排序算法也不例外。不过,针对排序算法的空间复杂度,还引入了一个新的概念,原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是 O(1) 的排序算法。
排序算法的稳定性
这个概念是指,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
比如有一组数据 2、9、3、4、8、3按照大小排序之后就是 2、3、3、4、8、9。
这组数据里有两个 3。经过某种排序算法排序之后,如果两个 3 的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
冒泡排序(Bubble Sort)
1 | def bubbleSort (data) |
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
- 冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为
O(1),是一个原地排序算法。 - 在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
- 最好情况下,要排序的数据已经是有序的了,只需要进行一次冒泡操作,就可以结束了,所以最好情况时间复杂度是
O(n)。而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行 n 次冒泡操作,所以最坏情况时间复杂度为O(n²)。
插入排序(Insertion Sort)
首先,将数组中的数据分为两个区间,已排序区间和未排序区间。
初始已排序区间只有一个元素,就是数组的第一个元素。
插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。
重复这个过程,直到未排序区间中元素为空,算法结束。
插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,还需要将插入点之后的元素顺序往后移动一位,腾出位置给元素 a 插入。
1 | def insertSort (data) |
- 插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是 O(1),也就是说,这是一个原地排序算法。
- 在插入排序中,对于值相同的元素,选择将后面出现的元素,插入到前面出现元素的后面,保持原有的前后顺序不变,所以插入排序是稳定的排序算法。
- 如果要排序的数据已经是有序的,并不需要搬移任何数据,这种情况下,最好是时间复杂度为
O(n)。注意,这里是从尾到头遍历已经有序的数据。如果数组是倒序的,每次插入都相当于在数组的第一个位置插入新的数据,所以需要移动大量的数据,所以最坏情况时间复杂度为O(n²)。
- Post title:排序算法(sort)
- Post author:Varsion
- Create time:2020-08-06 23:08:11
- Post link:https://blog.varsion.cn/post/dc2be8e4.html
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.