归并排序和快速排序

归并排序和快速排序,这两种排序算法适合大规模的数据排序,时间复杂度均为 O(nlogn)。
归并排序
如果要排序一个数组,先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
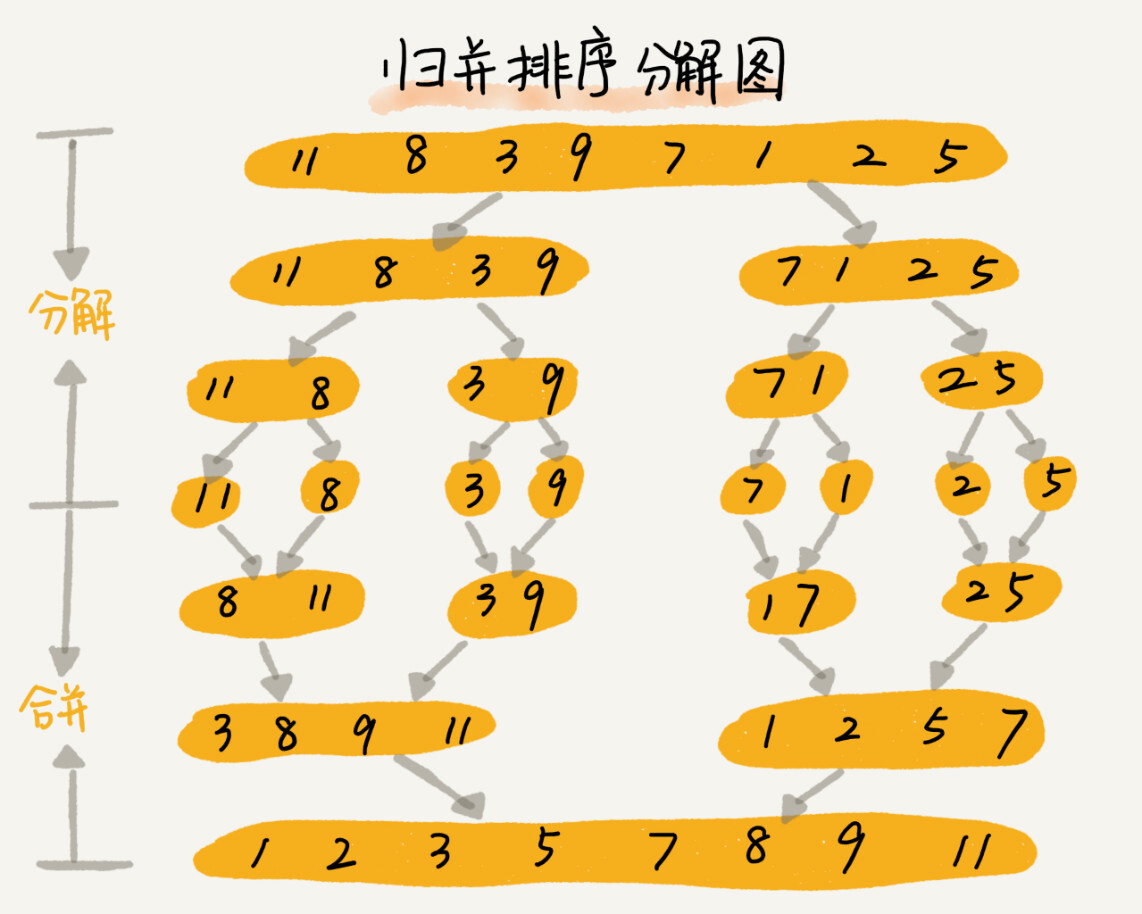
算法思路
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复上一步骤直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾
1 | def merge (list) |
归并排序的性能分析
- 归并排序是一个稳定的排序算法
- 归并排序不是原地排序算法
- 归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是
O(nlogn)。 - 临时内存空间最大也不会超过 n 个数据的大小,空间复杂度是
O(n)
快速排序
快排利用的也是分治思想。看起来,它有点像归并排序,但是思路其实完全不一样。
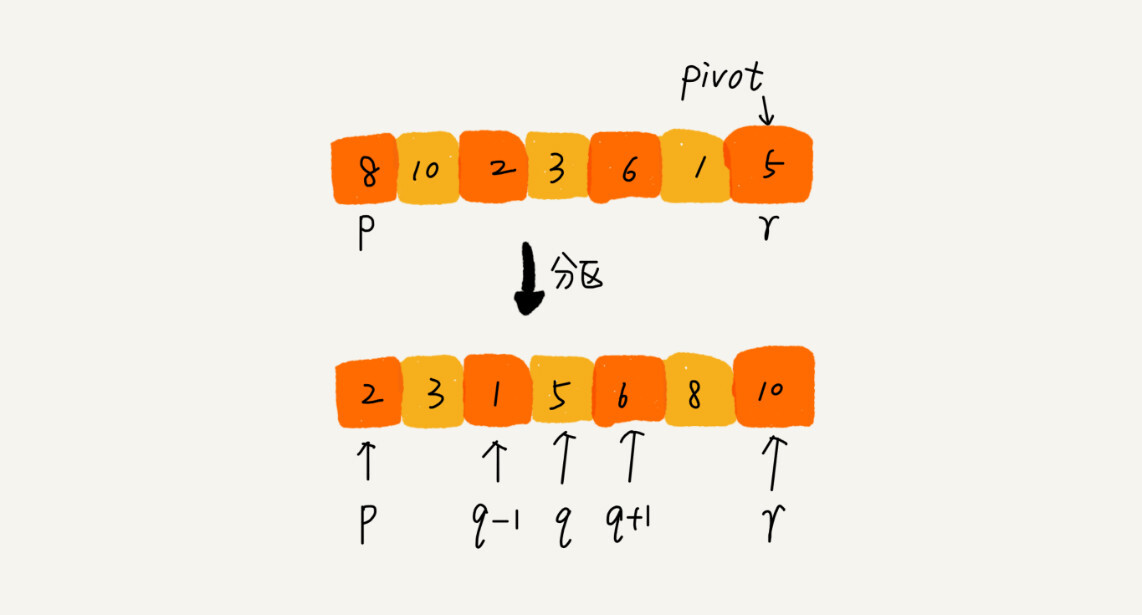
快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
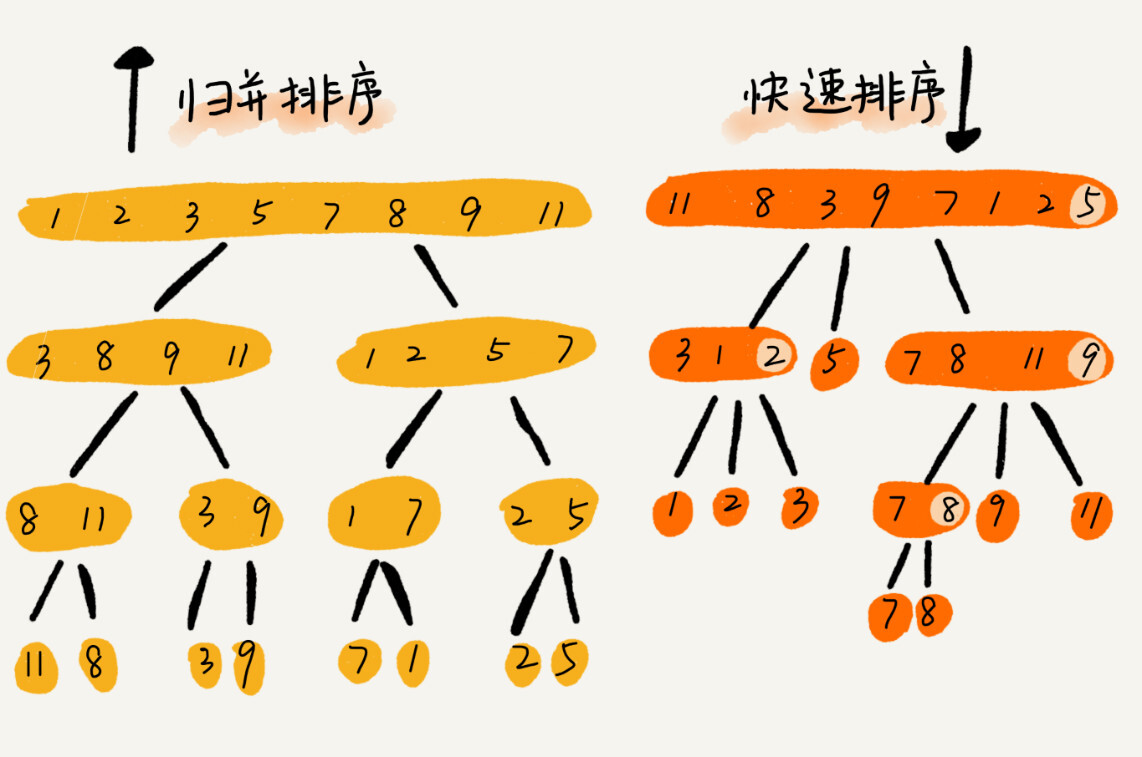
归并排序的处理过程是由下到上的,先处理子问题,然后再合并。
而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。
归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。
快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
- Post title:归并排序和快速排序
- Post author:Varsion
- Create time:2020-08-07 16:02:45
- Post link:https://blog.varsion.cn/post/8e1d135f.html
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments